De levenscyclus van analytische informatie (epiloog)
De promotie van analytische oplossingen van ontwikkel- en proeffase naar een stabiel productiestadium is een zoektocht. Het werkt net even anders dan de rapportage- en analyseomgevingen rond een data warehouse, de verantwoordelijkheden liggen vaak decentraal in de organisatie.
De vraag “hoe weet ik wanneer ik een analytische oplossing onder robuust beheer moet brengen?” verklaart waarom het een zoektocht is.
In de voorgaande delen van de serie is uitgebreid aan bod gekomen dat de interactie tussen informatieconsumenten en informatieproducenten afhankelijk is van het gebruikspatroon. In het deel “De rol van context, de bron van alle complexiteit” wordt de distributiegraad van informatie en de levenscyclus geïntroduceerd.

Wat dat betekent voor het beheren van informatieproducten wordt niet uitgewerkt. Ik laat het bij de mededeling dat “de relatie met de gebruikspatronen is complex, de distributiegraad speelt altijd wel een rol.”
Dit deel gaat in op hoe die relatie ligt en hoe je daar in de besturing van de informatiecyclus mee om kan gaan.
De stappen in het proces van informatieverwerking tot informatietoepassing
Voor besturing van de levenscyclus is het nodig om het proces van informatieverwerking te begrijpen. Toepassen van informatie is iedere keer het doorlopen van hetzelfde proces: data wordt geprepareerd, geduid en gebruikt. In geval van herhaalde toepassing probeer je het proces van prepareren zo veel mogelijk te automatiseren en het proces van duiden iedere keer te beperken. Het maakt het gebruik van informatie effectiever, wat het creëren van waarde bevorderd.
Hoe verloopt dit proces?
- prepareren is de data gebruiksklaar maken. Dat is zowel transformeren, distribueren als toegankelijk maken.
- duiden is interpreteren. Duiden is geen eenduidig proces, dit is waar mensen consensus vinden over de betekenis van informatie en tot welke actie dit leidt. Duiden is een groepsproces waarin zowel ontwikkelaars, data scientists, analisten als gebruikers participeren.
- gebruiken is de conclusie trekken op basis van de duiding en het acteren op die conclusie. Hier wordt de waarde geoogst die de informatie heeft.
Om dit proces soepel te laten verlopen moet je het proces aansturen. Het ingeburgerde woord hiervoor is ‘governance’.
In het connected architectuur raamwerk valt prepareren onder IT governance, duiden onder informatieverwerking governance en gebruiken onder informatievalorisatie governance.
De levenscyclus van informatie
Informatie en informatiegebruik is niet statisch. Dat is de reden dat je niet alleen het informatieverwerkingsproces moet besturen, maar ook de veranderingen in de toepassing van informatie.
Er zijn veel manieren waarop je de levenscyclus kan beschrijven. Ik hak hem op in drie generieke delen:
- ontstaan: het ontwikkelen van nieuwe ideeën, het toetsen van aannames, het iteratief ontwikkelen van nieuwe informatieproducten. Niet alle ideeën of producten hebben blijvende waarde. Vaak blijkt na verificatie een aanname niet valide blijkt te zijn. Soms is de waarde beperkt tot eenmalig gebruik. Alle ad-hoc vraagstukken blijven in de ontstaan fase.
- gebruik en groei: de fase waarin producten herhaald van nieuwe data voorzien worden. Een mate van robuustheid is nodig en het proces wordt bij voorkeur geautomatiseerd. Er blijven aanpassingen en uitbreidingen aan het product. Door voortschrijdend inzicht van de duiding kan het product aanpassing nodig hebben. De integriteit van het product moet geborgd worden.
- buiten gebruikstelling: de fase waarin een informatieproduct geen waarde of relevantie meer heeft en buiten gebruik wordt gesteld. In de praktijk is dit de fase waar veel te weinig aandacht voor is. Beheerorganisaties zijn tijd en geld kwijt aan het onderhouden van niet gebruikte producten.
De informatielevenscyclus en de gebruikspatronen
Alle informatie doorloopt de levenscyclus, maar in de gebruikspatronen komt niet iedere fase voor. Gedurende de levenscyclus kan een informatieproduct van het ene gebruikspatroon naar het andere gebruikspatroon verhuizen. Wat betekent dat?
Het is goed om te bedenken dat de gebruikspatronen niets anders zijn dan een classificatie van informatiegebruik, waarbij de interactie tussen informatieproducenten en informatieconsumenten verschilt. Het gevolg is dat de invulling van de governance, de besturing op het effectief laten verlopen van het proces, anders is. In de ontstaansfase moet je een beeld vormen onder welk gebruikspatroon de gebruik en groei fase valt. Het interactiepatroon stelt de eisen waar het informatieproduct aan moet voldoen.
Voor de gebruikspatronen toezicht houden, verantwoordingsinformatie en analyse weten we heel goed hoe dit moet. De ervaring met business intelligence heeft ons die kennis gebracht.
Het vraagstuk waar veel organisaties mee worstelen is hoe dit te doen voor de gebruikspatronen voorspelling en dataonderzoek. Maar is dit wel zo anders?
Het enige gebruikspatroon waarbij op voorhand niet duidelijk is aan welke voorwaarden een product moet voldoen in de gebruik en groei fase is in dataonderzoek. Dataonderzoek heeft geen eigen gebruik en groei fases, vanuit dataonderzoek is de volgende fase altijd één van de vier andere gebruikspatronen. Verder kan vanuit voorspelling een product evolueren tot iets wat onder toezicht houden valt.
Als op voorhand niet duidelijk is waarheen een informatieproduct evolueert, is de consequentie dat de technische opbouw van het product gedurende de levenscyclus moet wijzigen om aan andere eisen te voldoen. Een (gedeeltelijke) herbouw is vaak noodzakelijk om het beheer en gebruik goed te kunnen regelen. Dit is niet de enige reden waarom de voorwaarden kunnen wijzigen.
De consequentie van verandering in de distributiegraad van informatie in de levenscyclus
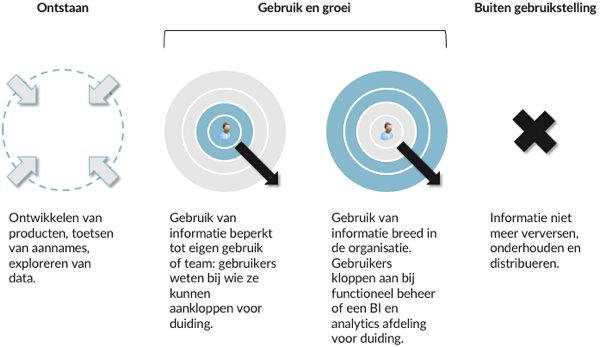
Met de verruiming van de distributiegraad van informatie verandert het beheer van die informatie:
- Je wilt de verversing van de informatie en de distributie automatiseren. Juist in gebruik van informatie, informatievalorisatie governance, is de tijdige beschikbaarheid van informatie van groot belang.
- Dat betekent dat de duiding van de informatie veel meer gefixeerd moet zijn en vaak als onderdeel van de informatie gedistribueerd wordt. Door de distributiegraad is de afstand tussen gebruiker en kennishouder of analist groter.
- Het doorvoeren van veranderingen, het releasemanagement, moet formeler om de consistentie en de robuustheid van informatie te borgen.
Dit leidt tot andere IT governance: professionalisering van het beheer is aan de orde. Dat vraagt om andere skills: je moet de producten dusdanig technisch opbouwen dat ontwikkelaars deze kunnen overdragen aan beheerders, of in een DevOps situatie zo min mogelijk tijd aan beheer kwijt zijn. Dat zorgt ervoor dat ontwikkelaars en beheerders samen veel en diverse informatieproducten beschikbaar kunnen houden, zonder dat de kosten lineair stijgen met het aantal informatieproducten onder beheer.
Met andere woorden, de governance op zowel informatiegebruik als informatieverwerking moet geformaliseerd worden met de verandering in distributiegraad in de levenscyclus.
Formaliseren van governance over de levencyclus fasen heen
Hoe zorg je voor een passende mate van formaliteit, afhankelijk van waar je in de levenscyclus zit?
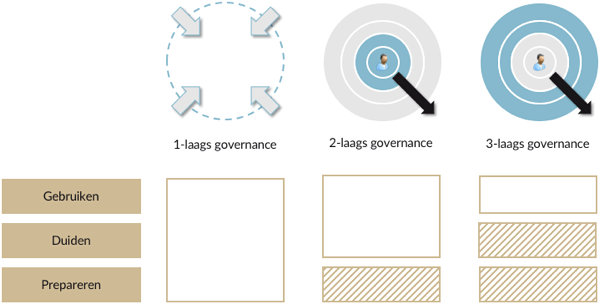
In de ontstaan fase is één team verantwoordelijk voor gebruiken, duiden en prepareren. In dat team participeren gebruikers, ontwikkelaars, data scientists en analisten. Er is veel communicatie nodig in deze fase, de interactie is zo fluïde mogelijk.
Waar mogelijk gebruikt het team onder IT governance beheerde data. Je wilt bij voorkeur hier gebruik van maken, het wiel opnieuw uitvinden heeft geen waarde en vertroebelt de eenduidigheid. Dat betekent dat onder IT governance de data ook beschikbaar gemaakt moet worden voor ontwikkeling en exploratie, zonder dat het de ontwikkeling en interactie beperkt.
De ontstaan fase wordt afgerond en het informatieproduct moet regelmatig ververst worden met nieuwe data en verspreid onder gebruikers. Onder welk beheer regime moet het product geplaatst worden? Dit is afhankelijk van de distributiegraad.
In geval van lokaal gebruik kunnen gebruikers de duiding en de toepassing van informatie zelf besturen, daar is geen formele beheer partij voor nodig. De data preparatie verloopt vaak geautomatiseerd en wordt formeel beheerd.
Dat betekent niet dat er een laissez-faire politiek wordt gevoerd, maar dat de verantwoordelijkheid voor de handhaving van afspraken, de governance, bij de gebruikers is gelegd. Wie, wat doet in duiden en gebruiken van informatie regelen ze zelf. Je kan argumenteren dat dit de definitie van ‘self service’ is, maar het is in dit model niet een gegeven dat de gebruiker aan de knoppen zit. Het kan best een analist of een data scientist zijn die aan de knoppen zit, het gaat in dit model om wie zeggenschap heeft en de mate van formalisering van de governance en de overdracht tussen verschillende groepen die ieder een deel van de informatieketen onderhouden.
De duiding moet geformaliseerd worden wanneer de distributiegraad zo groot is dat een gebruiker niet meer weet bij wie hij of zij kan aankloppen om een vraag verduidelijkt te krijgen. Dat vraagt om professionaliteit in het beheer. Er wordt een knip gelegd in de formele governance op het gebruik van informatie en de formele governance op het verwerken van data, in termen van duiden en prepareren. Informatieproducten doorlopen een releasemanagement traject om eenduidigheid te borgen. De producten komen onder IT governance regels, net als de data preparatie.
IT goverance en het vraagstuk van data science en data lakes
Terugkerend naar de startvraag, wat betekent dit voor analytische oplossingen waar data scientists een rol spelen?
De gebruikspatronen dataexploratie en voorspelling vragen om een andere interactie tussen gebruikers en producenten van informatie. Het verschil in interactie zit in duiding en gebruik, niet zozeer in data preparatie.
Hoe je met data preparatie omgaat is meer afhankelijk van de levenscyclus fase.
Het betekent dat we in analytics en data science niet een hele andere benadering van het beheren en besturen van informatie nodig hebben. De principes zijn hetzelfde, alleen de skills en de programmatuur is anders. De antwoorden kennen we al, we moeten ze alleen aanpassen op een nieuw onderdeel in het informatiespectrum. IT moet kennis opdoen in het beheren van voorspelmodellen, zoals ze dat ook voor ETL en rapportages hebben gedaan. Data scientists moeten in hun ontwikkel standaarden professionaliseren, zoals de BI mensen dat ook hebben moeten leren.
Er is veel toegevoegde waarde in hergebruik van data die al onder IT governance is. Zelfs binnen het dataonderzoek patroon is er een mix van eenduidige, goed beheerde data omgevingen en verzamelde data waarvan de waarde nog onzeker is. Een data lake is geen noodzaak, maar hooguit een middel voor een beperkt aantal use cases.
De uitdaging in de praktijk is dat IT governance vaak verkrampt is en ‘dat mag niet’ een veelgehoord antwoord is. Het data lake wordt dan het middel om IT te omzeilen.
De noodzakelijke verandering is veel meer dat gebruikers de verantwoordelijkheid moeten pakken om rechtmatig gebruik onderling af te dwingen. De IT kramp is de resultante van het afwijzen van die verantwoordelijkheid, waardoor IT gedwongen wordt om voor gebruikers beslissingen te nemen. Het gevolg is dat alle governance geformaliseerd wordt, ook als het niet passend is en zelfs knellend wordt.
Uiteraard spelen belangen en persoonlijkheden een rol, maar dat is in elk governance model en situatie. Dat maakt de noodzaak tot verandering er niet minder om. Of je het governance model goed ingeregeld krijgt bepaalt of je waarde uit data gaat halen of niet.