The life cycle of analytical information (epilogue)
Promoting analytical solutions from the development and test phases through to the stable production stage is a search. It works just that little bit differently from reporting and analysis environments based on data warehouses, as the responsibilities are often organised in a decentral way.
The question “how do I know when I can put an analytical solution into a robust maintenance situation?” explains why this is such a search.
The interaction between information consumers and information producers depending on use patterns, has been explained extensively in previous articles in this series. The article “The role of context as the source of all complexity”, introduced the information distribution levels and life cycle.

What this means for maintaining information products isn’t explained in depth in that article. Suffice it to say that “the relationship with use patterns is complex, as distribution levels always play a role”.
This article goes into more depth about this relationship and how you can deal with it while managing the information life cycle.
The stages from information processing up to information application
You don’t need to understand the process of information processing to manage the life cycle. Applying information means going through the same process again and again: data is prepared, made sense of and used. Where data is refreshed, you try to automate the preparation process as much as possible and to limit the sense making process each time. This makes the use of information more effective, which also promotes value creation.
How does this process work?
- preparation means making the data ready for use. This means transformation, distribution and making the data accessible.
- sense making means interpreting. Sense making is no simple process, this is where people need to reach a consensus about what the information means and which action it leads to. Sense making is a group process, in which developers, data scientists, analysts and users participate.
- usage means drawing conclusions from the sense making and acting on these conclusions. This is when the value contained in the information can be harvested.
You need to manage this process for it to proceed smoothly. The standard term for this is ‘governance’.
In the connected architecture framework, preparation is part of IT governance, sense making is part of information provisioning governance and usage is part of information valorisation governance.
The information life cycle
Information and information use are not static. That is the reason that you not only need to manage information processing processes but also changes in the way that information is applied.
There are many ways that you can describe the life cycle. I divide it into three generic sections:
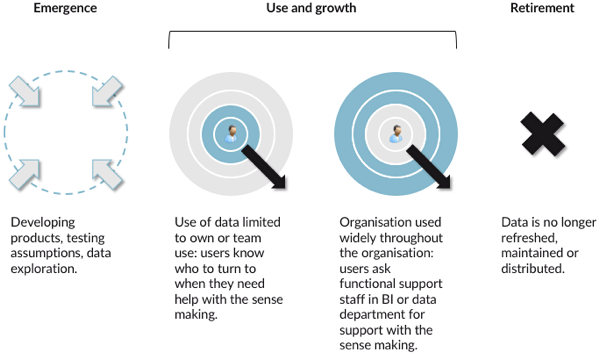
- emergence: developing new ideas, testing assumptions, iterative development of new information products. Not every idea or product shows lasting value. Often, an assumption proves invalid after verification. Sometimes the value is limited to one-time use. Ad-hoc requests remain in the emergence phase.
- use and growth: this is the phase when products are repeatedly provided with new data. A certain amount of robustness is required, and the process should preferably be automated. Adaptations and extensions to the product keep taking place. As a result of advancing insights in the sense making, the product may require adaptations. The integrity of the product needs to be guaranteed.
- retirement: in this phase, the information product is no longer valuable or relevant and is taken out of use. In practice, there is too little attention paid to this phase. Maintenance organisations spend money and time maintaining unused products.
The information life cycle and use patterns
All types of information go through the life cycle, but not every phase exists in all the use patterns. During the life cycle, an information product can move from one use pattern to another use pattern. What does that mean?
It’s good to realise that use patterns are nothing other than a classification of information usage, where the interaction between information producers and information consumers differs. The result is that the implementation of governance, the management of ensuring that the process runs effectively, differs. In the emergence phase, you need to gain a picture which use patterns the usage and growth phase will fit into. The interaction pattern makes the demands which the information product will need to meet.
We are well aware how this needs to be done for the use patterns monitoring, accountability reporting and analysis. Experience with business intelligence has given us that knowledge.
The issue that many organisations struggle with is how to do this for the use patterns prediction and data research. But how different are these in actual fact?
The only use pattern for which the product conditions are unclear before the usage and growth phase is data research. Data research has no own usage and growth phases; the next phase following data research is always one of the four other use patterns. A product can also evolve from prediction into a monitoring use case.
If it is unclear beforehand what an information product is evolving into, the consequence is that the technological construction of the will need to change to meet other demands during the life cycle. A (partial) reconstruction is often required to arrange maintenance and usage sufficiently. This is, however, not the only reason that conditions can change.
Consequences of change in information distribution levels during the life cycle
As the distribution level of the information changes, so does its maintenance:
- It’s advisable to refresh information and to automate distribution. It’s precisely when information is used, information valorisation governance, that the timely availability of information is of great importance.
- This means that the sense making of the information has to be far more fixed and often needs to be distributed as part of the information. The distance between the user and the knowledge keeper or analyst grows alongside the distribution level.
- Implementing changes, release management, needs to be more formal to guarantee the information’s consistency and robustness.
This leads to another kind of IT governance: making maintenance more professional is now required. This needs other skills: you have to be able to build the products technically so that developers can transfer them to maintenance staff or so that maintenance takes as little time as possible in a DevOps situation. This ensures that developers and maintenance staff can keep many and diverse information products available, without these costs rising in linear proportion to the number of information products being maintained.
To put it in other words: the governance of both information usage and information processing needs to be formalised along with the changes in distribution levels in the life cycle.
Formalising governance throughout the phases of the life cycle
How can you ensure an appropriate amount of formality, depending on your position in the life cycle?
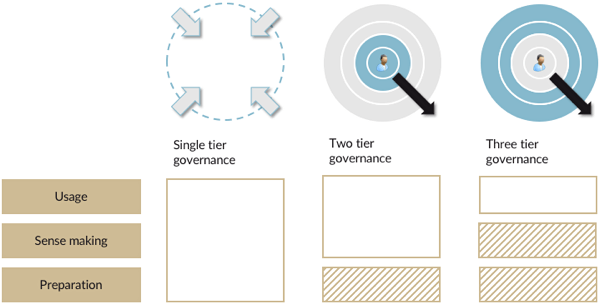
In the emergence phase, there is one team responsible for usage, sense making and preparation. Users, developers, data scientists and users participate in that team. There is a great deal of communication needed in this phase and the interaction should be as fluid as possible. Wherever possible, the team makes use of data which has been maintained under IT governance. It is advisable to make use of this, because reinventing the wheel is of no value and obscures unambiguity. This means that the data needs to be made available for development and exploration within IT governance, without that restricting the development or interaction.
The emergence phase has now been completed, and the information product needs to be refreshed regularly with new data which is distributed amongst the users. Which maintenance regime should apply to this product? That depends on its distribution level.
If the usage is local, then users can manage the sense making and application of information themselves; no formal maintenance party is needed for this. Data preparation often takes place in an automated manner and is managed formally.
This doesn’t mean that laisser-faire rules, rather that the responsibility for enforcing the agreements, the governance, has been assigned to the users. They themselves arrange who does what for the sense making and usage of the information. You could agree that this is the very definition of ‘self-service’, but this model doesn’t assume that it is the user who is steering the ship. It might well be an analyst or a data scientist steering; this model is more concerned with determining who has a say, the extent of formalisation of governance and the transfer between various groups, who are all maintaining one link of the overall information chain.
When the distribution level becomes so large, that a user no longer knows who he or she needs to approach when they have a question requiring clarification, sense making needs to be formalised. This requires professional maintenance. A distinction needs to be made between the formal governance of information usage and the formal governance of the data processing, in terms of sense making and preparation. Information products proceed through a release management process to guarantee unambiguity. The products then fall under IT governance rules, just as data preparation does.
IT governance and the issue of data science and data lakes
Returning to our original question, what does this mean for analytical solutions, in which data scientists have a role? The use patterns data exploration and prediction require a different kind of interaction between the users and producers of information. The difference in interaction lies in sense making and usage, not so much in data preparation.
How you deal with data preparation depends more on your life cycle phase.
This doesn’t mean that we need a completely different approach to maintaining and managing information in analytics and data science. The principles remain the same, it’s only the skills and the software used which are different. We already know the answers, we just need to adapt them to a new aspect in the information spectrum. IT needs to gain knowledge about maintaining predictive models, just as they have done for ETL and reporting. Data scientists need to become more professional in their development standards, just as the BI people have also had to learn to do.
There is a great deal of added value to reusing data which already falls under IT governance. Even within the data research patterns, there is a mix of unique, well maintained data environments and data collections with as yet unknown value. A data lake is not a necessity, but at most a means to an end for a limited number of use cases.
The challenge in practice is that IT governance is often tense, an often-heard answer being ‘that’s not allowed’. The data lake then becomes a way of avoiding IT.
The change that’s needed is that users need to take hold of the reins and their responsibility and enforce mutual usage in the right way. The IT tension is the result of them rejecting this responsibility, so that IT is forced to take decisions on the users’ behalf. The result of this is that all governance becomes formalised, even if that isn’t appropriate and even if it becomes oppressive.
Naturally, interests and personalities also play a role, but that is true of every governance model and situation. This doesn’t reduce the need for change. The determining factor for if you are going to be able to harvest value from the data is how well you have set up your governance model.