Connecting people in connected architecture
Data related initiatives are often laborious. Obtaining, adapting and maintaining information solutions takes more effort than you would like. The through time of projects is increasing. In the series “the complexity of data projects” I explained what causes this.
One of the consequences is that the call for data governance is increasing. If you look on the internet, you’ll find that one half of data related articles is about the blessings of data technology and the other half is telling you that you are doomed to failure if you haven’t set up your data governance properly.

A lot of data governance projects fail, despite the need for them being recognised. Opportunism is flying high, so that splintered information landscapes has become a reality. How can you avoid this?
It turns out we’re only human after all
I think the solution lies in recognising how people work and what our human nature is.
- If you are judged by your (assigned) contribution in achieving goals, you will start to behave accordingly. You’ll ignore, either consciously or unconsciously, anything that doesn’t contribute to these, even if it is important.
- Everyone has their own personal motivations and professional interests. What you like and what you can control is what you end up doing, everything else quickly feels like an obligation.
- As an individual you have a limited and often coloured view of life and work.
You need to exchange information to reach consensus about the status quo. Institutionalising these exchanges into organisational processes and supporting them with technology helps you to reach a higher plane together. It appears that we can go beyond our own limitations when we work as a team.
Arriving at a unique definition of information in a corporate environment is not easy
Before we investigate how we can incorporate human nature into solutions, I think it would be useful to reflect on what makes it so difficult to get data governance up and running.
Barry Devlin has given us the answers with his Modern Meaning Model (m3 model) and I would advise you to read the article in the link.
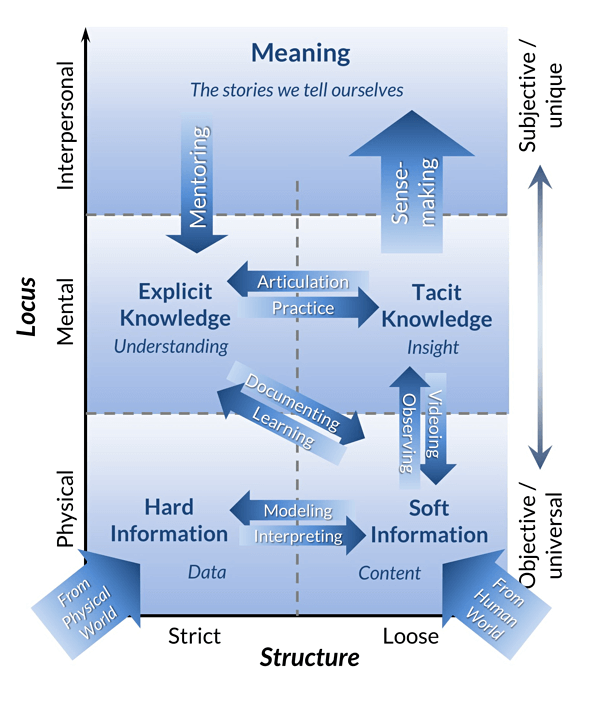
Image of the m3 model reproduced with permission of Barry Devlin.
Data governance is the management of clarity, of meaning, of information, so that exchanging information leads to improving operational management as effectively as possible and so that no incorrect conclusions can be drawn from the information. It doesn’t matter whether this is information for managing business processes, such as in BI or analytics, or the use of information in the business processes. The process of arriving at a consensus takes place at the top level of this model. The process called ‘sense making’ means that a large group of people need to arrive at an agreement about what the information means. Data or ‘hard information’ in the model, is the raw material which we feed into the process of sense making.
What we then try to do in BI is to record the consensus about the meaning in information solutions so that this consensus can be distributed as hard information (data).
This is where a lot of data governance initiatives run aground, because they omit the human process, the mental level in the model. You won’t make an effort to acknowledge the impact of your interpretation of information on your colleagues, if you are not working on the same goals or in the same part of the organisation. Nobody will judge your performance on this: you cannot have an overview of the impact. If data governance is then made mandatory by ‘others’ who are working on the problem, then it has no connection to your personal interests or motivations. In actual fact, it restricts your room to manoeuvre and your freedom.
If you won’t do it, then I will!
What you then see in practise, is that the technical people who work with the data (hard information), take on the responsibility of determining what clarity is on behalf of the information consumers. They will decide for you in what shape the information products will be delivered to you. The individual interests of individual users converge at this point, so the technical staff have more insight into the coherence between business processes, how these are expressed in the data and the consequences of inconsistent information on information consumers arriving at a consensus about what the next action should be.
And that’s where it goes wrong. The technical people are only people after all, who don’t act any differently than information consumers. They can’t know the users’ context completely and their personal motivations lie much more in taming the data. They are judged on their ability to make data available, not on the way it is used. You end up with a contrast between users who consider this annoying and developers who think that users are abdicating responsibility. If this goes on for long enough, the dire lament strikes up about the unwillingness and slowness of IT.
Users start working around IT, without worrying about maintenance issues and splintered data landscapes are the result. Opportunistic behaviour is a product of our human nature.
So, how then?
The solution lies in organising the institutionalisation of information usage management differently. In “creating tailwind for your data organisation” I went into this structure. To be successful, the organisation of information and the responsibility lie with the information consumers. So, why is this a condition for success?
Structured and persistent conversation is the only way to achieve mutual understanding and to maintain it. An understanding that consensus in the sense making of information can only evolve by talking about it. An understanding that there is a need for consensus about recording the sense making in data, in dashboards, in briefings, in explanatory texts, in videos, in PowerPoint presentations, in word documents and in the data definitions used to build IT applications. This is the ‘mentoring’ in m3 model.
The process of recording involves people with different skill sets, like analysts and developers. Information consumers from different parts of an organisation are responsible to decide what information is relevant to everyone and what information is only relevant for a selected group. Prioritising this is a continuous effort and should be driven by the users. This needs to be organised.
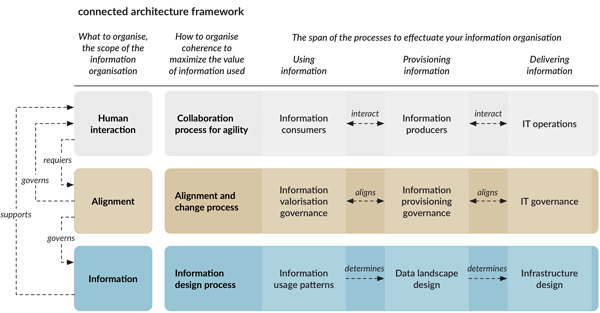
Putting the organisation into practise is where it gets difficult. The difficult point is the switch between information valorisation governance and information processing governance. This is where our mental processes, the shaping and application of knowledge from the m3 model, human nature and the importance of a joint agreement about the meaning of information collide. From the m3 model, we know that we make sense of hard information differently through differences in knowledge fed by our experiences and personal interests.
The process of agreement takes a lot of time and energy and it is a continuous exercise. You need to keep investing in maintaining the joint areas, because before you know it, everyone relapses into their own personal interests. That is quite understandable. It is just like with children: taking toys out of the toybox to play with them is fun but clearing up definitely isn’t. Teaching children the discipline to do this is a combination of tenacity, reward and punishment and in this way conditioning the behaviour until it has become a habit. That is no different with data governance.
The trick is to allow users to teach each other this discipline; the data-technical people can bring their insights about the consequences of a lack of consensus to the table and are also allowed to determine when users aren’t taking enough responsibility and when the data environment is threatening to become inconsistent.
Working together is a fluid process over time
The more people who are involved, the slower the process becomes. So, you need to think carefully about when the mutual aspects are really important. Differentiation in use patterns, the distribution level of information and insight into the information life cycle is of essential importance to determine this.
Throwing all the data into a data lake and letting everyone grab at it, is the equivalent of completely emptying the toybox. After a while, the room is in complete chaos.
Consensus needs to be found about the use context of the individual users where management covers multiple departments or multiple business processes. In this situation, joint governance is needed. Where information and the interaction about consensus takes place in the same use context, data governance is no less needed, but the form in which it should take place can be organised by the users themselves.
Because the relevant information can change over time, it is important to keep actively making agreements and to keep talking to one another. In practise, you see that after a while, everyone relapses into human habits. We think that we have it all organised, but we’re only human after all. Data entropy is the consequence of that human behaviour.
To stop this happening, limit the set which needs to be formally agreed upon. You shouldn’t keep buying toys and filling the toy box to the brim, but also decide what can be thrown away. Parents are often well aware that it is sensible to allow their children to add a new toy if they themselves choose what can be thrown away. I imagine that quite some adults reading this now can remember from their own childhood, just how tricky this is. Data in organisations is no different, despite the technology which makes collecting petabytes of data child’s play.
The greatest benefit is being aware that there is a balance to be found between formal data governance and informal data governance. Where this balance lies changes over time and it is always the result of a continual conversation between information users and producers.