Wind mee organiseren voor de data organisatie
Data is alleen waardevol door toepassing van inzichten verkregen uit data.
De verantwoordelijkheid voor de organisatie van de datahuishouding ligt daarmee bij degenen die de inzichten toepassen, zij weten wat ze nodig hebben.

In veel organisaties worstelen BI afdelingen, BI competence centers, analytics afdelingen en IT afdelingen met de organisatie van hun informatievoorziening. Voor veel professionals voelt het alsof hun kennis en vaardigheden niet goed benut worden, omdat ze geen verbinding voelen met de gebruikers voor wie zij hun informatieproducten maken. Andersom ervaren gebruikers dat er veel gepraat wordt over het belang van data, maar vinden ze dat hun IT afdeling niet levert.
Het BI competence center (BICC) werd rond de eeuwwisseling geïntroduceerd als middel om die impasse te doorbreken. Sindsdien zijn veel BICC organisaties in de IT organisatie gevormd. De situatie is vaak marginaal verbeterd.
Data als begrip staat stevig op de agenda van management teams, directies en raden van bestuur en het tij is gunstig om de organisatie rond toepassing van data te stroomlijnen.
Het organiseren van data en de naam die je er aan geeft
Er is begripsinflatie en begripsverwarring ontstaan rond business intelligence, business analytics, (big) data, artificial intelligence en machine learning. Voor het belang van de toepassing maakt het niet uit hoe je het noemt of welke techniek er gebruikt wordt om data te raffineren en bruikbaar te maken voor de beoogde toepassing. Uiteraard heeft het type toepassing wel invloed op de interactie tussen informatiegebruikers en informatieverwerkers. De serie “de complexiteit van informatieprojecten” gaat hier uitgebreid op in.
Dit artikel gaat over de organisatie van de interactie. Begripsinflatie leidt bij mensen soms tot het gevoel dat BICC geen adequate naam meer is.
Ik laat het aan een ieder wat de best passende naam is binnen hun organisatie. Ik probeer een neutrale aanduiding te gebruiken in deze tekst.
Hoe organiseer ik wind mee?
Als toepassing van inzichten verkregen met data het belangrijkst is, dan moet daar waar de toepassing en de vraag ontstaat de verantwoordelijkheid voor prioritering van de vraag en toepassing van de resultaten georganiseerd worden. Het motto is “voor de gebruikers, door de gebruikers”. Degene die voor de toepassing van informatie verantwoordelijk is, heeft ook de verantwoordelijkheid voor de totstandkoming van passende informatieproducten.
Als je dat als uitgangspunt neemt ligt het belang en het mandaat in elkaars verlengde. Dat verzekert je van wind mee.
De weerbarstige praktijk van alledag
Het klinkt zo simpel, maar de praktijk laat zien dat het niet makkelijk is. In veel gevallen wordt de verantwoordelijkheid bij de IT organisatie gelegd onder het motto “data is toch een IT ding?”
Vanuit IT bottom-up het gebruik van data organiseren kan, maar het is met tegenwind. Als IT organisatie heb je geen mandaat om het gebruik van de data af te dwingen. Veel IT organisaties willen dat mandaat ook helemaal niet hebben.
Je komt er uiteindelijk wel, maar het is een lang en moeizaam proces. In de praktijk is de druk van de technologische vernieuwing op organisaties zo groot, dat dit bottom-up proces te lang duurt, waardoor gebruikers van informatie het heft in eigen hand nemen. Vanuit hun perspectief levert IT niet wat ze nodig hebben.
Verantwoordelijkheid nemen is de gewenste situatie, maar het leidt in de praktijk vaak tot punt oplossingen die de korte termijn behoefte afdekken. Gebruikers begrijpen niet hoe je een datalandschap goed structureert en ordent. Een explosie aan deeloplossingen en informatiechaos is het gevolg. Aan de IT organisatie de ondankbare taak om dat in de lucht te houden.
Informatieverwerkers voelen zich gepasseerd. Het zijn vakmensen met beroepstrots en in de schaarse markt voor talent gaan ze op zoek naar een omgeving die wel ontvankelijk is.
Hoe pak je het dan wel aan?
Hoe houd je wind mee?
Gebruikers van data is geen homogene groep met gelijke belangen. Hoe organiseer je dan de verantwoordelijkheid?
Je kan deze het best splitsen in twee delen:
- Informatie valorisatie governance: Informatievragen op waarde prioriteren, toezien op het gebruik van gerealiseerd informatieproducten en de toepassing van de inzichten, zodat de investering rendeert.
- Informatieverwerking governance: het samenwerkingsmodel tussen de gebruikers en de informatieverwerkers in het definiëren, maken, beheren en gebruiken van informatieproducten.
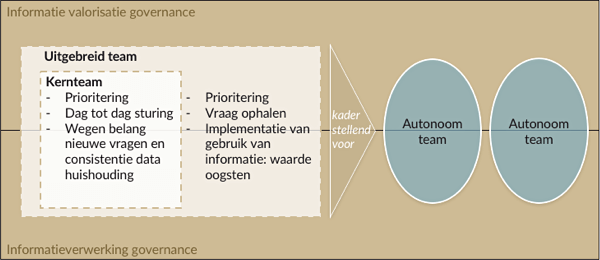
De tegenstellingen van de verschillende gebruikers moet je bij elkaar brengen en het is aan hen om onderling de balans te zoeken. De organisatie van de informatievraag bestaat uit:
- Een kernteam voor de dag tot dag sturing en naast prioritering van de vraag ook de de datahuishouding op orde houdt. Je hebt te maken met complexe IT omgevingen. Noodzakelijk onderhoudswerk moet ook voldoende aandacht krijgen wil het datalandschap veranderbaar blijven tegen aanvaardbare kosten en doorlooptijd.
- Een uitgebreid team waarin vertegenwoordigers van de verschillende gebruikersgroepen zijn vertegenwoordigd. Zij moeten gezamenlijk bepalen wat de prioriteiten zijn, waarbij eigen belangen en organisatiebrede belangen onderwerp van onderhandeling en weging zijn. De vertegenwoordigers in het uitgebreid team zijn ook verantwoordelijk voor de implementatie: de waarde oogsten met de informatieproducten die opgeleverd zijn. Die verplichting balanceert de belangen in het proces van prioriteren. De vertegenwoordigers hebben het mandaat om gebruikers vrij te maken om te participeren in de teams die de informatieproducten opleveren als deze van de prioriteitenlijst opgepakt worden.
De vraag is altijd groter dan productiecapaciteit. De vraag verandert ook in de tijd. Dat betekent dat prioriteren een regelmatig terugkerend proces is.
De productiecapaciteit wordt verdeeld over onderwerpen die bedrijfsonderdeel overstijgend zijn en bedrijfsonderdeel specifiek zijn. Bedrijfsonderdeel specifieke onderwerpen leveren immers ook waarde voor de hele organisatie.
Het kernteam bewaakt de spelregels om de informatievalorisatie governance en de informatieverwerking governance in samenhang te brengen en te houden, gevoed vanuit de prioriteiten die samen met het uitgebreide team bepaald wordt. Daarmee zijn zij kaderstellend voor de teams die informatieproducten maken en onderhouden.
De informatieverwerking governance bestaat uit spelregels voor hoe samenwerking van gebruikers en informatieverwerkers in teams georganiseerd is en uit kaders waar informatie oplossingen aan moeten voldoen. De kwaliteit van wat teams leveren en de doorlooptijd van hun levering is mede afhankelijk van de kwaliteit van de feedback loop in het team. Door gebruik van informatie wordt scherper wat echt nodig is en kunnen informatieoplossingen hogere waarde leveren doordat ze aansluiten bij de toepassing. Door een nauwe samenwerking binnen een autonoom team zijn de communicatielijnen zo kort mogelijk en wordt snijverlies door overdrachtsmomenten zo veel mogelijk beperkt.
Het waarom is duidelijk, maar wie, wat , waar en hoe doe ik dit?
Het voert te ver om op deze plek uiteen te zetten hoe de invulling van de teams eruit ziet, welke rollen er onderkend worden, hoe een kader eruit ziet voor een autonoom team en hoe je afstemming tussen teams organiseert als de kaders knellen.
Er is antwoord op die vragen, ze zijn een aspect van het grotere connected architectuur raamwerk en het onderwerp van volgende publicaties.