Creating tailwind for your data organisation
Data gets value by applying the insights derived from it. Therefore, the responsibility for organising data is with the people who apply the insights. They know what information they need.

The BI departments, BI competency centres, analytics departments and IT departments of most organisations struggle with organising information provisioning. Many professionals are disconnected from the users they create the information products for, leaving them with a feeling of undervaluation of their skills and knowledge.
The flip side of the coin is users feeling abandoned by their IT departments. In their view IT does not deliver, despite a lot of talk about the importance of data.
The BI Competency Center (BICC) was introduced around the turn of the century as a means to break through the standstill. Many BICC organisations have since been formed within IT departments. It has improved the situation marginally.
Data, as a notion, has conquered the top spot of the agenda of management teams and boards of directors. The signs are favourable to streamline the data organisation.
The name given to the data organisation
Terminology juggling has confused people. The valuation of terms like business intelligence, analytics, (big) data, artificial intelligence and machine learning has become almost personal. To stress the importance of data, it doesn’t matter what label you stick on the technology used for refining and transforming data and prepare it for use. The kind of use it concerns does influence the interaction between information consumers and information producers. The series “The complexity of information projects” address these interactions.
The focus of this article is on how to organize this interaction. Some people feel that the label BICC doesn’t cut it anymore as a result of terminology juggling. It is up to you what name befits data efforts within your organisation. In this article, I use a neutral ‘data organisation’ as a label.
How do I create tailwind?
If applying insights derived from data is most important, then the place the application happens is the spot where responsibility for prioritising demand and implementing the insights must be organised. The slogan is “For the users, by the users”. Who is responsible for applying the insights also has the responsibility to organise the provisioning of the information as is fit for use.
If this is the position, the interest and the mandate are in line. This generates the tailwind for your data efforts.
The harsh reality
It sounds simple, but everyday reality proves otherwise. IT is often appointed to be responsible, motivated by “data is typically an IT thing”.
It is possible to organise the use of data bottom-up from IT, but it is with headwind. An IT department is not mandated to enforce the use of data. Most IT organisations do not even want to have this responsibility assigned to them.
In the end, you will get there, but it is a long and difficult process. The pressure on organisations by technological progress is real. As a result, the bottom-up process takes too long for users and they start to organize data technology themselves. IT is too slow and too bureaucratic from their point of view.
Users taking responsibility is what you want, but the problem is that they create short-term silo solutions. Users do not comprehend how to structure a data landscape for coherence and longevity. As a result, an explosion of partial and partially overlapping solutions emerges and information chaos ensues. IT is forced into the ungrateful position to keep the chaos alive.
Information professionals, often employed by IT departments, feel ignored. They have their professional pride and in this scarce market for their skills, they search for organisations who are more appreciative.
So, how do you setup the data organisation?
How to keep tailwind
The users of data are not a homogenous group with equal interests. How do you organize their responsibility?
The responsibility can be split up in two parts:
- Information valorization governance: prioritizing information demand on the value it adds, governing the use of information products delivered, and the implementation of insights derived from it. Information valorization governance should deliver return on investment of the information products.
- Information provisioning governance: the interaction models between information consumers and producers in defining, developing, maintaining and using information products.
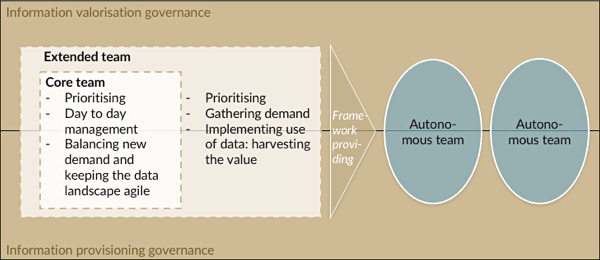
The interests of users, which can be opposite or similar, must be joined. It is up to them to find a balance. To facilitate this, the data organisation consists of
- A core team responsible for operational management, demand being prioritized and keeping the data household tidy and agile. The IT environment is complex. Maintenance needs to get proper attention to secure changeability of the data landscape, at acceptable cost and with acceptable lead times.
- An extended team which consists of representatives of each user group. Together, they need to set priorities, negotiating and balancing their own group interests and organisational interests. The representatives are also responsible for implementation, meaning harvesting the value of information products delivered. Having this responsibility counterbalances the pushing of private agendas in the priority setting process. The representatives are mandated to free up resources in their own user groups, to participate in teams building information products.
Demand will always outgrow production capacity. Demand changes in time. The consequence is that priority setting is a repeating process.
The production capacity available is distributed across organizational and departmental topics. Departmental topics also add value to the organisation and should get equal priority.
The core team sets the rules of the game to align information valorization and information provisioning governance, where the priority setting process requiers the alignment process. This way, the core team and extended team set the boundaries for the teams that build and maintain information products.
Information provisioning governance is both the rules of the game for collaboration of information consumers and information producers, and the framework of requirements set for information products. The quality of delivery of teams and their time-to-market of information is set by the quality of the feedback loop organised within the team. The experience gained by using information pulls into focus what is of value. Based upon this experience, information products can be better fitted for use and deliver higher value. The communication between users and producers is as direct as possible through real collaboration within teams, avoiding information loss through disconnected knowledge transmission.
The why is clear by now, but with who, when and how do I achieve this?
This is not the place to explain what teams look like, which roles should be represented in a team, how to create boundaries for an autonomous team, and how to organise alignment between teams when the boundaries become restrictive.
There is an answer to all these questions, they are part of the larger connected architecture framework and the subject of future publication.