Naakte Data
Datamanagement is nog steeds een weerbarstige discipline. Uitleggen waarom dat zo is, niet zo makkelijk. Ik las twee artikelen die op het eerste gezicht niet zo veel met elkaar te maken hebben, maar terwijl ik over de inhoud nadacht zag ik een verband dat de weerbarstigheid deels verklaard. Wat ik zag is dat we om een tekortkoming in technologie heen werken. Dat leidde tot een idee van hoe een passende technologische oplossing eruit zou moeten zien, willen we ooit uitkomen op het punt dat technologie naadloze ondersteuning biedt aan de manier waarop mensen met informatie werken. Alle bestaande technologieën voelen ruw aan, het lijkt vaak op het opbouwen van een bruidstaart met een graafmachine.

Als eerste las ik Barry Devlin’s artikel over context, waarin hij de term ‘naakte data’ introduceert. Het artikel benadrukt het belang van context van informatie en hoe we daar mee worstelen in technologie. Vervolgens las ik het uit twee delen bestaande artikel (deel 1 en deel 2) van Noreen Kendle, waarin ze treurige staat van data management beschrijft. Van de fundamentele factoren die ze beschrijft komt de ‘bedrijfsuitvoering – data connectie’ steeds bovendrijven. Kort uitgelegd is de ‘bedrijfsuitvoering – data connectie’ de mate van bekendheid met informatie die mensen ervaren en daaruit voortvloeiende de mate van bruikbaarheid van informatie voor hun vraagstukken.
De fundamentele uitdaging van informatiegebruik
Na tientallen jaren computerondersteunde informatievoorziening zou je denken dat we inmiddels wel begrijpen hoe we onze data moeten managen. In de praktijk beginnen mensen onrustig met hun voeten te schuiven als iemand de gevreesde woorden ‘data governance’ laat vallen. In de woorden van Noreen Kendle, de kloof in de ‘bedrijfsuitvoering – data connectie’ blijft groeien.
Dat heeft een logische verklaring. Ik gebruik onderstaande afbeelding om het uit te leggen.
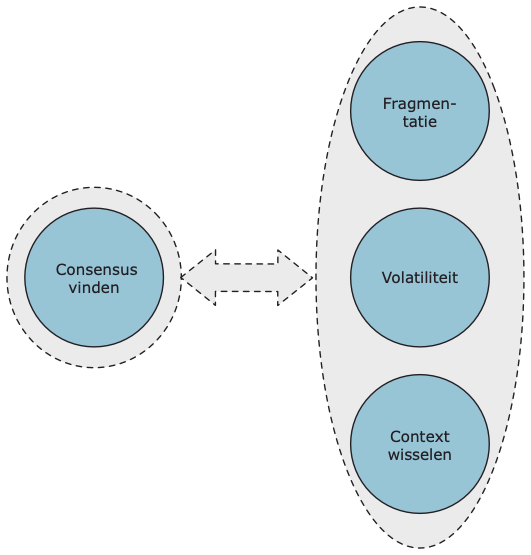
Fragmentatie en volatiliteit zijn exponentieel gegroeid met de mogelijkheden om grote hoeveelheden data op te slaan en te verwerken.
Fragmentatie is de verspreiding van data over een immer groeiend aantal opslagplekken. Fragmentatie weerspiegelt ook het aantal mensen met verschillende vaardigheden dat betrokken is in de keten van informatiebevoorrading. Volatiliteit is het aantal wijzigingen in zowel de informatievraag als in het technologisch landschap.
We kunnen steeds meer data opslagplekken bereiken. Technologie heeft het verzamelen van nieuwe categorieën van data mogelijk gemaakt, bijvoorbeeld de data van de sensors in een horloge. Je zou denken dat we met al die mogelijkheden veel enthousiasme opbrengen om data zorgvuldig te beheren. Het tegenovergestelde is gebeurd, we worden erdoor overweldigd.
In de jaren 70 waren stafafdelingen in bedrijven die zich bezighielden met het verzamelen en analyseren van data, op papier, heel gewoon. Dat was een arbeidsintensief proces en data was een kostbaar bezit. Als staflid had je ongekend veel kennis nodig van je eigen bedrijf en de sector waarin het bedrijf actief is. Je wist waar je data aan kon boren om vragen te beantwoorden.
De technologische vooruitgang heeft tot hyperspecialisatie geleid. In de reis van de registratie van data tot het toepassen van inzichten zijn verschillende mensen met gespecialiseerde kennis en vaardigheden actief. Het staflid dat alles deed is vervangen door wel drie of vier mensen in de keten. Ieder persoon in de keten voelt zich verantwoordelijk voor dat deel waar ze mee bezig zijn, maar vaak hebben ze geen idee tot welk eindresultaat het werk geleid heeft. Ik ontmoet iedere dag ontwikkelaars die geen idee hebben van wat de belangrijke thema’s en vraagstukken zijn in de organisatie waar ze werken. De gebruiker van de inzichten heeft geen flauw benul welk pad de data heeft afgelegd. Voor hen is het ‘zullie van IT’ die ‘onbegrijpelijke dingen doen die altijd veel te veel tijd nemen’.
Fragmentatie en volatiliteit zijn het resultaat van technologische voortgang en de effecten die dit heeft op de structuren van bedrijven en markten. De evolutie naar een passend governance model om het gat te dichten in de ‘bedrijfsuitvoering – data connectie’ is achterbleven. We proberen dat gat te dichten met nog meer technologie. Nieuwe ontwikkelingen, zoals AI ondersteunde data duiding, helpen ons om de weg te vinden in de gigantische aantallen datapunten die worden vastgelegd, maar de echte uitdaging is gelegen in menselijke samenwerking. Connected architectuur is een model dat dit probleem onderkent en dat wijst op een datamanagement benadering die passend is voor de hedendaagse wereld met alom aanwezigheid van data.
Het kunnen gebruiken van data in verschillende contexten is de grootste inherente uitdaging aan werken met informatie en meestal worden daar niet veel woorden aan vuil gemaakt. Het is precies het fenomeen van context wisselen waar technologie ons hopeloos in de steek laat.
Context is allesbepalend
Data is het resultaat van informatie die binnen een bepaalde context wordt vastgelegd. Gemeten temperatuur is data, maar de context kan medisch, meteorologisch of zoiets simpels als het barbecueën van een steak zijn. Als je duizenden gebakken steaks wilt analyseren op een breed scala van barbecues, zodat je kan bepalen welke barbecue de meest voorspelbare resultaten geeft, is temperatuur één van de variabelen die je kan gebruiken. De context van het vergelijken van barbecues is een andere context dan de initiële gebruiksreden: iemand die wil weten wanneer de steak gaar is. Dit is context wisselen. We doen het ongemerkt, de hele tijd. Het wordt pas problematisch als we met een groep mensen tot een eensluidend oordeel moeten komen wat de beste barbecue is.
Hoe relateert context aan data die wordt vastgelegd? Neem als voorbeeld de hartslag in slagen per minuut. Onder welke omstandigheden is de hartslag vastgelegd? Is iemand in een diepe slaap of juist wanneer iemand actief is? En gedurende activiteit, wat is de bron van de meting? Ziekenhuisapparatuur, bijvoorbeeld om de revalidatie van iemand na een hartoperatie te volgen of je Fitbit? En is de hartslag op je Fitbit gemeten terwijl je op een zonnige lenteochtend naar je werk fietst of op een winderige herfstdag met ladingen boodschappen aan je stuur en je tegen de klok racet om je kinderen van school op te halen?
De naakte data is de meting van de hartslag in slagen per minuut op een tijdstip, de rest is context. En context is allesbepalend als je data wilt selecteren of analyseren. Gebruik van data voegt zelfs nieuwe context toe. Ben je de weerstand van een nieuw type fietsband aan het onderzoeken en gebruik je de hartslag van fietsers als een maatstaf voor de hoeveelheid weerstand die ze ondervinden of onderzoek je de oorzaak van hartfalen onder jongvolwassenen? Dat maakt zeker uit in hoe je met data omgaat.
Context is allesbepalend. En de databases die we gebruiken om data vast te leggen en te verwerken, zijn notoir slecht in het vastleggen van context of het scheiden van context van naakte data. In de serie ‘de complexiteit van informatieprojecten’ ga ik in op wat het proces van verzamelen, verwerken en gebruiken van analytische informatie zo weerbarstig maakt. Vanuit datamanagement oogpunt is de technologie die we tot onze beschikking hebben matig, zeker vergeleken met wat ons menselijk brein aankan bij het verwerken van context.
Hoe kan technologie ons helpen in plaats van tegenwerken?
Naakte data zonder context is waardeloos. Als we data willen herinterpreteren, om welke reden dan ook, zijn we gedwongen om eindeloos data te kopiëren en transformeren over verschillende vormen van data technologie heen of binnen onze databases. Om het nog erger te maken is de context die we kunnen vastleggen met data in een database rudimentair. Je moet een gedreven data professional zijn, met affiniteit voor IT en veel begrip van huidige en toekomstige bedrijfsvraagstukken, om technologie voor datagebruik te ontwerpen en te bedienen.
Hoe zou de oplossing eruit moeten zien wil het de ‘bedrijfsuitvoering – data connectie’ kloof overbruggen?
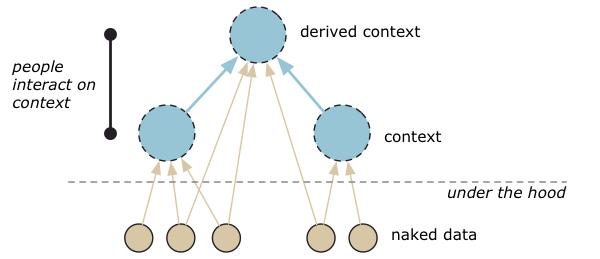
De technologie zou ons in staat moeten stellen om alleen met context te werken. De connectie tussen naakte data en context moet buiten zicht en onder de motorkap gebeuren, zonder dat er menselijke tussenkomt noodzakelijk is. Context is breed scala aan informatie, maar de technologie moet ons in staat stellen om het allemaal vast te leggen en gebruiken:
- Informatie oorsprong – de methode waarmee de informatie is verzameld, waar het is vastgelegd, wanneer het is vastgelegd, waarom het is vastgelegd en de variatie in de vastlegging.
- Informatie betekenis – de beschrijving van wat de naakte data representeert.
- Informatie doel – de omstandigheden waarin informatie is vastgelegd of waarvoor het is getransformeerd. Cruciale informatie als we data willen selecteren of filteren.
- Informatie consensus – vastleggen van de verschillende meningen over de interpretatie van de betekenis van informatie.
Klinkt dit vergezocht? Ik denk van niet. Het gemiddelde Word document of e-mail systeem kan bovenstaande informatie vastleggen, maar het gemiddelde Word document of e-mail systeem scheidt niet de naakte data van de context, waardoor het onmogelijk is om de informatie te filteren en te aggregeren naar een andere context toe. Laat staan dat we de nieuw ontstane context weer kunnen vastleggen.
De enorme technologische progressie in analytische systemen doet je wensen dat ze steeds beter passen bij hoe wij mensen met informatie omgaan, maar ik ben bang dat dit punt nog ver achter de horizon ligt.