Gartner’s logisch data warehouse: mijn interpretatie van het concept
Ik heb Gartner’s logisch data warehouse altijd als een concept beschouwd: stof tot nadenken. Het raamwerk is opgebouwd uit verzamelde waarnemingen van hoe organisaties veranderd zijn in hun datamanagement uitvoeringspraktijk. Het raamwerk voedt de discussie over modern datamanagement voor analytics toepassingen.
Het logisch data warehouse is een denkproces, geen recept
Het recept om van een logisch data warehouse een werkend systeem te maken is niet bijgeleverd. Je moet zelf het concept vertalen in een passende architectuur en gaan nadenken hoe je die architectuur gaat invullen. Jouw gebruikstoepassingen, eisen en capaciteiten op gebied van informatie governance bepalen wat een passende architectuur is.
Het raamwerk helpt je om alle aspecten te benoemen en richting te geven aan gesprekken over wat passend is. Vooral de interactie tussen de verschillende logische componenten in het raamwerk en de consequenties van die interactie zijn belangrijk. Je wordt zo gedwongen om het plaatje in z’n geheel te blijven bekijken en je niet te verliezen in details.
Waar bestaat het logisch data warehouse concept uit?
De visualisatie van het concept staat in onderstaande afbeelding.
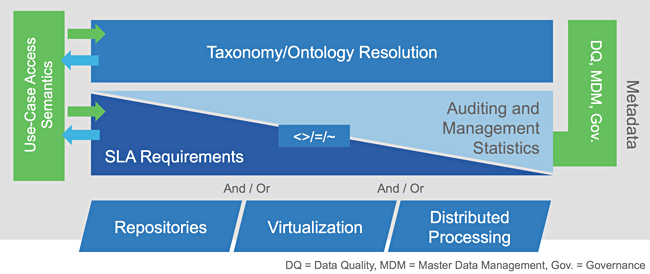
Zonder al te veel de tekenwijze te willen duiden vallen er een paar aspecten op:
- Het grijze blok start halverwege de drie schuine blauwe blokken onderaan. Het impliceert dat het logisch DWH meer over het bovenste gedeelte gaat dan over de technologie van dataopslag en -transport.
- Een groot deel van het logisch DWH bestaat uit componenten die de nadruk leggen op gebruik van, toegang tot en consistentie van betekenis van informatie. Het omvormen van de data naar het datamodel is belangrijker dan technologie waarmee dat uitgevoerd wordt.
Ik denk dat het concept iets anders benadrukt dan de technologie die meestal de aandacht krijgt als je zoekt op de term ‘logical data warehouse’. Die nadruk is geen verrassing, de meeste white papers zijn geschreven door technologieverkopers en de consultancy partijen die deze technologie implementeren. Concepten levert meestal geen cashflow op. Vrijwaring: voor ons ook niet.
Een logisch data warehouse is een virtueel data warehouse, toch?
Het merkwaardige is dat ‘logisch’ vaak vertaald wordt als ‘gevirtualiseerd’. In de afbeelding staat duidelijk dat het logisch data warehouse een mix van technologieën kan gebruiken.
‘Repositories’ betekent data warehouses, data marts of andere databases, ‘virtualization’ betekent verschillende technologieën om data bijeen te brengen en te transformeren over databases heen en ‘distributed processing’ betekent alles van middleware tot ETL om hetzelfde te doen.
Eén, twee van de drie of alle drie vormen samen de infrastructuurbasis waarop de decompositie van de data warehouse functies in logische componenten is gebaseerd: een ecosysteem van samenwerkende oplossingen. De drie schuine boxen in de afbeeldingen is de abstracte weergave van dat ecosysteem.
Het beheren en reguleren van toegang tot de data is lastig als het overal en nergens is opgeslagen en via verschillende processen bij elkaar gebracht wordt. Het bovenste deel van de afbeelding gaat over deze uitdaging.
Voor verschillende gebruikstoepassingen zijn andere oplossingen nodig.
Verschillende gebruikstoepassingen, van financiële rapportage tot ad hoc exploratie van gegevens, stellen andere eisen aan het datamodel. Een datamodel dat bestaat uit gegevenssets die verspreid zijn over databases. Iedere set aan gegevens komt met andere SLA eisen, afhankelijk van de gebruikstoepassing.
Wat exact bedoeld wordt met ‘taxonomy/ontology resolution’ is voer voor vrijdagmiddagborrels van architecten, maar ik gok erop dat ze het proces van betekenis en context geven aan data niet willen beperken tot de woorden ‘data modelleren’. Data modelleren wordt meestal geassocieerd met relationele gegevens.
Aan dezelfde informatie kunnen andere eisen gesteld worden op gebied van toegangsbeheer, gegevenskwaliteit en traceerbaarheid, afhankelijk van de gebruikstoepassing. Je hebt software nodig die je helpt om aan die eisen invulling te geven en gegevens te presenteren volgens een datamodel dat vooral op logisch niveau bestaat, maar geïmplementeerd is over een samenraapsel van fysieke databases en datatransport componenten.
De eisen kunnen overeenkomen of haaks staan op de beschikbaarheidseisen en beheersbaarheid eisen zoals vastgelegd in de SLA. Naar mijn menig is dat de betekenis van de middelste rechthoek in de afbeelding waarin een ‘is ongelijk’, ‘is gelijk’ en ‘bij benadering’ teken staan.
Dit staat voor mij voor de kern van het logisch data warehouse concept. Je moet je steeds de vraag blijven stellen hoe om te gaan met de soms tegenstrijdige eisen aan toegankelijkheid, beschikbaarheid, beheersbaarheid en gegevenskwaliteit, gebruikstoepassing afhankelijk, binnen een gedistribueerde architectuur.
Het logisch data warehouse concept dwingt je op voorhand over complexiteit na te denken.
Complexiteit is het monster dat ons iedere keer weer bedreigt met grote enterprise data warehouse projecten. De toegevoegde waarde van het logisch data warehouse concept is juist het op voorhand nadenken over complexiteit: je moet de afbeelding van boven naar beneden lezen, niet van beneden naar boven.
Gartner’s logisch data warehouse concept vertelt ons dat er niet één oplossing is die aan alle eisen tegemoet kan komen. Een gedistribueerde architectuur is het antwoord op de complexiteitsvraag, waarbij je de consequenties van een gedistribueerde architectuur voor data governance en toegankelijkheid van gegevens niet licht mag opvatten.