Secured Data Container method, a pragmatic approach for dealing with sensitive data in a BI environment
Processing sensitive data is a challenge in most BI environments.
You can categorise sensitive data into business sensitive data and data subject to compliance. Business sensitive data is marked as sensitive by the owners of the data. An example is cost price calculations. Legislation drives what data is subject to compliance rules. An example is all data concerning privacy.
Implementing rules for sensitive data is a moving and fuzzy target
Legislation like GDPR does not translate directly into a solution or design. Use of data is permitted or restricted by use case and has not a direct link to a record in the database. This prevents creating clear guidelines for building data warehouses.
Separation of concerns also complicates implementing guidelines. Security Officers, Privacy Officers and legal departments have the responsibility to create policies on security and data and to assure the compliance to these policies. Since information security policies must be applicable to all sorts of IT systems, they are drawn up in generic terms.
Business intelligence developers are not trained to think in a legal way and have a hard time to translate the generic policies to the specific challenges they face in the BI domain. Conversations between legal officers and BI developers about pragmatic technical guidelines often feel like a Tower of Babel discussion. We try to understand each other but it is hard to find common ground.
To make matters worse, there are degrees of sensitivity. Privacy related data could be regarded more sensitive than quarterly revenue figures. Often, this distinction is not expressed clearly in the design of the data warehouse. You find yourself applying the strictest security to all data. This hampers the development effort on the data warehouse and the time to market for new demand.
Due to security restrictions, users feel it is a hassle to get the data they need from the BI environment. They will try and find other ways to get their information. In fact, they will do their utmost best to circumvent the security measures to get the data, thus rendering security measures obsolete.
Over time, laws, the interpretation of laws and the organisational attitude towards privacy related issues can and will change.
How to deal with all of this, without further complicating the maintenance, changeability or accessibility of the data warehouse and without incurring huge operational costs?
A method that helps you to deal with this complicated matter in a very simple way is the Secured Data Container method. It offers you a method to move along with changes in policies, but maintain a single implementation in a data warehouse. The Secured Data Container method helps you to create auditable examples of problem areas that anyone can comprehend. It enables a clear, fact based conversation between all parties involved.
The Secured Data Container method is a workable solution, not an answer to all challenges.
The method is not the definitive answer to all your security and privacy concerns. It is a proposal for a workable solution for managing sensitive data in a data warehouse. The method is data modelling approach agnostic, so it can be implemented in all data warehouses. Your legal officers still need to determine if this proposed solution is sufficient to meet the requirements set by their policies.
How can the Secured Data Container method help you?
- It is easy to implement and maintain containers for partitioning sensitive data in the data warehouse
- It offers different methods to screen sensitive data from users
- Limited impact when new sensitive data items are identified or added or when the method to screen data changes, even when being applied in retrospect
- It enables constructive communication between legal officers and developers through tangible examples.
What is a container?
A container is a group of tables which have the same security policy applied to it. A single container has one security policy. Between containers security policies differ.
A container can be implemented as a separate schema in the same database, a separate database in the same instance or as a database on a separate server. The appropriate choice is determined by the security policies of the organisation, each has its own challenges.
Implementing the Secured Data Container method
Add containers to the data warehouse to partition data on sensitivity
The approach is to create at least two containers with data in the data warehouse:
- A secured data container
- A general available data container.
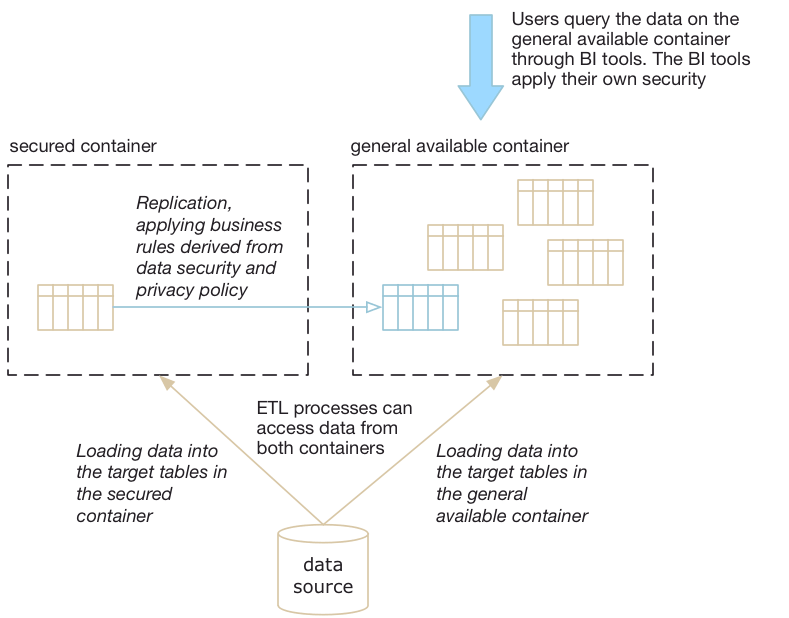
The first step is to determine which tables need to be stored in the secured data container.
- Tables without sensitive data are placed in the general available data container and loaded from the data source.
- Tables with sensitive data are placed in the secured container. The data is loaded from the data source to the secured container and replicated from the secured container into the general available container. In the replication process, the data is screened.
The assessment if a table contains sensitive data is a conversation between legal officers and developers and is guided by the data security policies.
Set the security policies
Different security policies are applied to the general available data container and the secured data container.
The general available data container offers access to the data warehouse with a uniform access model and security policy. The security is binary in nature in the database; access is granted or not. If a user or a tool has access to tables in the general available container it is on all tables. Additional, finer grained access rights can be granted within a BI tool.
The tables in the secured data container are not accessible through BI tools, but data is available for processing by ETL tools. If you need the real values for integration or calculation, the processing is within the secured data container and the results can be screened. This assumes you have permission to use the data for these purposes, otherwise there is no reason to load the data into the data warehouse environment in the first place. Access to this container is kept to a minimum and all access is system account based or name based. System account based access for ETL tools, name based accounts for developers and operations people, such as DBA’s. The name based access is needed for regular development, maintenance and troubleshooting operations.
The name based maintenance accounts are governed by additional policies to which people must comply and by audit trails that log all access and usage. If unavoidable, users who have clearance to use the actual data can get name-based accounts to query this data.
This is standard policy for most organisations, so adopting this approach will not meet much resistance.
Screen sensitive data from users
The next step is the crucial part of the method. Replicate the structure of the table in the secured container to the general available container. Data will be replicated applying one of the screening methods outlined in the table below. These methods do only apply to columns classified as sensitive. All other data can be copied over without modification.
| Screening method | Format of the data after the screening method has been applied | Consequences of using this screening method |
|---|---|---|
| Leave it blank | Data is not copied over at all. The column contains a NULL value. Example: the postal code ‘1234 AB’ becomes NULL | There is no data to use for aggregation or filtering in reports or analysis. Users unaware of the application of the rule might think there is an error in the data. |
| Obfuscating | Data is stored in an obfuscated way. For instance by replacing the value with four asterisk symbols. Example: the postal code ‘1234 AB’ becomes ‘****’ | Aggregation on this column will lead to one grand total of the measure against the value ‘****’. The column becomes useless for filtering the data. The format of the data clearly shows the user that the data is screened. |
| Pseudonyms | Actual or generated data is used to substitute the real values. In most applications of pseudonyms, actual values in a column are shuffled in random order over the rows. Example: the postal code ‘1234 AB’ becomes ‘5678 YZ’ | Users who are unaware of the pseudonyms and take the value for truth might jump to the wrong conclusions. The value looks ‘real’. This method is not recommended for production systems, but is often applied for acceptance testing of applications |
| Aggregation | Data is truncated or aggregated to an allowed level of visibility. Example: the postal code ‘1234 AB’ becomes ‘12’. | Filtering on these values is crude. Aggregates are not fine grained. This method is often applied when for instance the age of a person is represented as an age range. This method enables users to derive useful information from reports and analysis results within the limitations of use. |
Why do it this way? The granularity of your data is not compromised, which means all calculations are still valid on all other data. Individual records can be retrieved and inspected by users, which makes the implications of the application of data security policies very easy to communicate. Since all records are represented it is still possible for users to do reconciliations or other comparisons on the general available data items. Like most solutions, doing it the simple way makes your life a lot easier.
Changeability and communication advantages
Low impact of changes, even when applied in retrospect
Laws or perceptions on privacy issues change over time. It takes a while before these changes are reflected in new policies and new data governance rules. We have experienced more than once that new rules should be applied starting some date in the past. Using the outlined methodology, it is easy to apply these rules in retrospect, if you have the historical original data available in the secured container. Even if you have to move a table from the general available container to the secured container, the impact is relatively low. The structure of the table in the general available container won’t change, just the contents of the table. As a result, the impact is localised to one or a few ETL flows. The flexibility in changing existing rules or applying new security rules is high, while the implementation is straightforward.
The setup in containers enables you to define different retention policies for the data in both containers and thus comply with legal obligations. In many instances, you can keep anonymous or aggregated data for a longer period than you can keep the original records. Retention policies limit the application of rules in retrospect of course. Once the original data is deleted, it is hard to apply different rules to them.
Enabling communication between legal officers and developers through tangible examples
The flexibility in implementation helps the conversation between users, developers and legal officers during the development process. It is very easy to create a prototype of a report with the right security policies applied. Sit together, talk about interpretation of what the policies translate into, or point out the limitations in using the data due to policies applied.
Putting it into practice
Having a solution to address the resilient issue of sensitive data and being able to deal with its effects in an adaptable way alleviates the stress felt by BI developers. But where do you start?
My advice is to put the technical framework with containers in place first. Even when a discussion about privacy is still diffuse, it is easy to identify the tables that do contain sensitive data regarding privacy. Move those tables to the secured data container and copy over the data to the mirrored table in the general available data container without applying any screening methods. This won’t impact your existing reports.
Structure the discussion by making examples by applying different screening methods. This will help everyone. While the governance on sensitive data issues matures within your organisation, you can adjust the data stored in the secured container and get to a balanced set of screening methods applied to your data.
Over time, when new sources are added or different policies need to be applied to different groups of tables, you can add additional secured data containers. It keeps the implementation for each container straightforward and simple.